FAQ & Tutorials
VPS (Virtual private server) is considered as advanced setup. Basically this is setup on Linux, so you have to know some basic Linux stuff. There is no graphical interface, which makes it even more difficult for Linux beginners.
1. Get two months free credits on one of the following VPS providers:
Register at Hetzner
Register at Vultr
Register at Digital Ocean
Choose VM instance that has minimum 2 GB of ram memory. This will not work if you use arm based CPU VPS, or Raspberry Pi. You can take a look here how to compile Idena node for Raspberry Pi.
2. Once you register an account, you must enter your credit/debit card.
3. Chose Ubuntu 20.04 x64 as an operating system for your server.
4. Under your VPS console, you'll find your server IP ADDRESS and PASSWORD for root user. We will need those two to connect from your PC to VPS. Let's presume you are running Windows on your home PC.
5. Download Putty, and install it. It's a free program that will help you to connect and control your server.
6. Download this file connect.bat and save it on your desktop. Right click on it and Edit. If Windows ask if you want to run it, run it.
When connect.bat file is opened for editing in notepad, it will contain these lines
You need to change last line, to enter your IP_ADDRESS and PASSWORD from step 4. After that, save connect.bat and close Notepad.
7. Double-click on a connect.bat, it will ask you to confirm some key, say Yes.
8. Now that we are successfully logged into server, let's install Idena Manager. Idena Manager is a script that will make your node installation very easy.
As a first step, we need to switch to root user
sudo su
Enter your root password
Copy this line and paste it in Putty window by right-clicking anywhere in the window, then press enter
source <(curl -sL https://raw.githubusercontent.com/rioda-org/idena/main/idena-manager/install)
If instalation seem stuck for longer time, just try to hit enter couple of times
For us to continue, we need to know. Do you already have active Idena identity? Or are you just setting up node for a new identity?
a) If you have active Idena identity, we must find your private key on your PC, go to:
(best if you copy and paste this in some folders address) there you will find nodekey file. Open it with notepad and copy it.
ALSO, IMPORTANT, BACKUP THIS, THIS IS YOUR PRIVATE KEY, DON'T SHARE IT WITH ANYONE.
Put your nodekey here, which you copied in step above. Copy and paste this line in Putty window. This will install your node.
idena-manager add -n "PUT_HERE_YOUR_NODEKEY" -a "123"
confirm with enter when it asks you for a install location
ATTENTION: after you confirm location, it can take a few minutes for node to be installed. Be patient until you get new message
b) If you are setting up node for new identity, use this command
idena-manager add -n "" -a "123"
confirm with enter when it asks you for a installation location
9. Configure Idena client to use node on your VPS. Open Idena on PC, go to Settings>Node. Turn off "Run built-in node", turn on "Connect to remote node", set:
Node address:
Node API key:
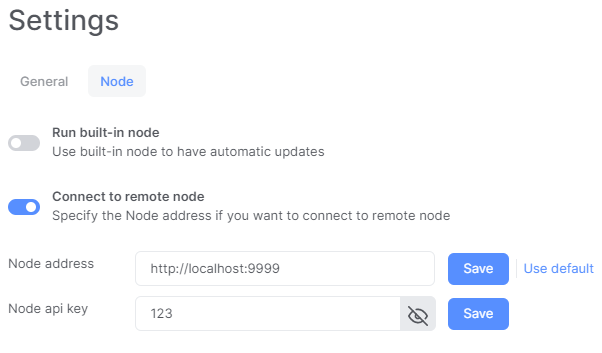
Save both settings
Now, when you go to client, you should see your identity/address/robot.
Now, you need to make connection every time you want to open Idena client on PC (when making flips, doing validation, sending coins etc...)
But node runs on VPS with or without Idena client or connection. So now you can turn off your PC and close Idena App.
This setup might take some time, make sure to check if mining is on, after all that you've done.
Installer will activate 1GB of swap file. That is virtual memory that can help VPS to run in cases RAM memory gets filled in rare cases.
Installer will also setup automine script that executes every 10 minutes.
From time to time, make sure to check if your hard disk is full
bash hdd
To see current node logs, use command:
bash log
Ctrl+C to stop it
To fix node database run command:
bash fixdb
1. Get two months free credits on one of the following VPS providers:
Register at Hetzner
Register at Vultr
Register at Digital Ocean
Choose VM instance that has minimum 2 GB of ram memory. This will not work if you use arm based CPU VPS, or Raspberry Pi. You can take a look here how to compile Idena node for Raspberry Pi.
2. Once you register an account, you must enter your credit/debit card.
3. Chose Ubuntu 20.04 x64 as an operating system for your server.
4. Under your VPS console, you'll find your server IP ADDRESS and PASSWORD for root user. We will need those two to connect from your PC to VPS. Let's presume you are running Windows on your home PC.
5. Download Putty, and install it. It's a free program that will help you to connect and control your server.
6. Download this file connect.bat and save it on your desktop. Right click on it and Edit. If Windows ask if you want to run it, run it.
When connect.bat file is opened for editing in notepad, it will contain these lines
@echo off
start "Putty" "C:\Program Files\PuTTY\putty.exe" -ssh -L 9999:localhost:9009 root@IP_ADDRESS 22 -pw PASSWORDYou need to change last line, to enter your IP_ADDRESS and PASSWORD from step 4. After that, save connect.bat and close Notepad.
7. Double-click on a connect.bat, it will ask you to confirm some key, say Yes.
8. Now that we are successfully logged into server, let's install Idena Manager. Idena Manager is a script that will make your node installation very easy.
As a first step, we need to switch to root user
sudo su
Enter your root password
Copy this line and paste it in Putty window by right-clicking anywhere in the window, then press enter
source <(curl -sL https://raw.githubusercontent.com/rioda-org/idena/main/idena-manager/install)
If instalation seem stuck for longer time, just try to hit enter couple of times
For us to continue, we need to know. Do you already have active Idena identity? Or are you just setting up node for a new identity?
a) If you have active Idena identity, we must find your private key on your PC, go to:
%appdata%\Idena\node\datadir\keystore(best if you copy and paste this in some folders address) there you will find nodekey file. Open it with notepad and copy it.
ALSO, IMPORTANT, BACKUP THIS, THIS IS YOUR PRIVATE KEY, DON'T SHARE IT WITH ANYONE.
Put your nodekey here, which you copied in step above. Copy and paste this line in Putty window. This will install your node.
idena-manager add -n "PUT_HERE_YOUR_NODEKEY" -a "123"
confirm with enter when it asks you for a install location
ATTENTION: after you confirm location, it can take a few minutes for node to be installed. Be patient until you get new message
b) If you are setting up node for new identity, use this command
idena-manager add -n "" -a "123"
confirm with enter when it asks you for a installation location
9. Configure Idena client to use node on your VPS. Open Idena on PC, go to Settings>Node. Turn off "Run built-in node", turn on "Connect to remote node", set:
Node address:
http://localhost:9999Node API key:
123Save both settings
Now, when you go to client, you should see your identity/address/robot.
Now, you need to make connection every time you want to open Idena client on PC (when making flips, doing validation, sending coins etc...)
But node runs on VPS with or without Idena client or connection. So now you can turn off your PC and close Idena App.
This setup might take some time, make sure to check if mining is on, after all that you've done.
Installer will activate 1GB of swap file. That is virtual memory that can help VPS to run in cases RAM memory gets filled in rare cases.
Installer will also setup automine script that executes every 10 minutes.
From time to time, make sure to check if your hard disk is full
bash hdd
To see current node logs, use command:
bash log
Ctrl+C to stop it
To fix node database run command:
bash fixdb
VPS (Virtual private server) is considered as advanced setup. This is setup on linux server. There is no graphical interface, which makes it even more dificult for linux beginners.
1. Get two months free credits on one of the following VPS providers:
Register at Hetzner
Register at Vultr
Register at Digital Ocean
Choose VM instance that has minimum 2GB of ram memory. This will not work if you use arm based CPU VPS, or Raspberry Pi. You can take a look here how to compile Idena node for Raspberry Pi.
2. Once you register account, you must enter your credit/debit card.
3. Chose Ubuntu 20.04 x64 as a operating system for your server.
4. Under your VPS console you'll find your server IP ADDRESS and PASSWORD for root user. We will need those two to connect from your PC to VPS.
5. Let's create connection file. Open up terminal (Ctrl+Alt+T). Run this command:
nano ~/connection
Then enter SSH connection command there
ssh -L 9999:localhost:9009 root@IP_ADDRESS
After that, save it (Ctrl+S), confirm it by pressing Y key and enter key.
7. Now while terminal is still up, let's connect to our VPS. Run this command:
bash ~/connection
It will ask you to confirm some key, confirm it. It will also ask you for a password for your VPS, enter it.
8. Now that we are successfuly logged into server, let's install Idena Manager. Idena Manager is script that will make your node instalation very easy.
Copy this line and paste it in Putty window by right clicking anywhere in the window, then press enter
source <(curl -sL https://raw.githubusercontent.com/rioda-org/idena/main/idena-manager/install)
For us to continue, we need to know. Do you allready have active Idena identity? Or are you just setting up node for new identity?
a) If you have active Idena identity, we must find your private key on your PC, run this command in new terminal:
nano ~/.config/Idena/node/datadir/keystore
It will show you your private key/node key. Copy it.
ALSO, IMPORTANT, BACKUP THIS, THIS IS YOUR PRIVATE KEY, DON'T SHARE IT WITH ANYONE.
Put your nodekey here, which you copied in step above. Run next command in VPS connected terminal. This will install your node.
idena-manager add -n "PUT_HERE_YOUR_NODEKEY" -a "123"
confirm with enter when it asks you for a install location
b) If you are setting up node for new identity, use this command
idena-manager add -n "" -a "123"
confirm with enter when it asks you for a install location
9. Configure Idena client to use node on your VPS. Open idena on PC, go to Settings>Node. Turn off "Run built-in node", turn on "Connect to remote node", set:
Node address:
Node api key:
Save both settings
Now when you go to client, you should see your identity/address/robot.
Now, you need to make connection (bash ~/connection) every time you want to open Idena client on PC (when making flips, doing validation, sending coins etc...)
But node runs on VPS with or without Idena client or connection. So now you can turn off your PC and close Idena App.
This setup might take some time, make sure to check if mining is on, after all that you've done.
As a last step, it does not hurt to add 1GB of swap memory to your server. That is virtual memory that can help your server if it runs low on RAM memory.
sudo fallocate -l 1G /swapfile2 && sudo chmod 600 /swapfile2 && sudo mkswap /swapfile2 && sudo swapon /swapfile2 && echo '/swapfile2 none swap sw 0 0' | sudo tee -a /etc/fstab
From time to time, make sure to check if your hard disk is full
df -h
To see current node logs use command:
tail -F log_stdout_node1.log
Ctrl+C to stop it
1. Get two months free credits on one of the following VPS providers:
Register at Hetzner
Register at Vultr
Register at Digital Ocean
Choose VM instance that has minimum 2GB of ram memory. This will not work if you use arm based CPU VPS, or Raspberry Pi. You can take a look here how to compile Idena node for Raspberry Pi.
2. Once you register account, you must enter your credit/debit card.
3. Chose Ubuntu 20.04 x64 as a operating system for your server.
4. Under your VPS console you'll find your server IP ADDRESS and PASSWORD for root user. We will need those two to connect from your PC to VPS.
5. Let's create connection file. Open up terminal (Ctrl+Alt+T). Run this command:
nano ~/connection
Then enter SSH connection command there
ssh -L 9999:localhost:9009 root@IP_ADDRESS
After that, save it (Ctrl+S), confirm it by pressing Y key and enter key.
7. Now while terminal is still up, let's connect to our VPS. Run this command:
bash ~/connection
It will ask you to confirm some key, confirm it. It will also ask you for a password for your VPS, enter it.
8. Now that we are successfuly logged into server, let's install Idena Manager. Idena Manager is script that will make your node instalation very easy.
Copy this line and paste it in Putty window by right clicking anywhere in the window, then press enter
source <(curl -sL https://raw.githubusercontent.com/rioda-org/idena/main/idena-manager/install)
For us to continue, we need to know. Do you allready have active Idena identity? Or are you just setting up node for new identity?
a) If you have active Idena identity, we must find your private key on your PC, run this command in new terminal:
nano ~/.config/Idena/node/datadir/keystore
It will show you your private key/node key. Copy it.
ALSO, IMPORTANT, BACKUP THIS, THIS IS YOUR PRIVATE KEY, DON'T SHARE IT WITH ANYONE.
Put your nodekey here, which you copied in step above. Run next command in VPS connected terminal. This will install your node.
idena-manager add -n "PUT_HERE_YOUR_NODEKEY" -a "123"
confirm with enter when it asks you for a install location
b) If you are setting up node for new identity, use this command
idena-manager add -n "" -a "123"
confirm with enter when it asks you for a install location
9. Configure Idena client to use node on your VPS. Open idena on PC, go to Settings>Node. Turn off "Run built-in node", turn on "Connect to remote node", set:
Node address:
http://localhost:9999Node api key:
123Save both settings
Now when you go to client, you should see your identity/address/robot.
Now, you need to make connection (bash ~/connection) every time you want to open Idena client on PC (when making flips, doing validation, sending coins etc...)
But node runs on VPS with or without Idena client or connection. So now you can turn off your PC and close Idena App.
This setup might take some time, make sure to check if mining is on, after all that you've done.
As a last step, it does not hurt to add 1GB of swap memory to your server. That is virtual memory that can help your server if it runs low on RAM memory.
sudo fallocate -l 1G /swapfile2 && sudo chmod 600 /swapfile2 && sudo mkswap /swapfile2 && sudo swapon /swapfile2 && echo '/swapfile2 none swap sw 0 0' | sudo tee -a /etc/fstab
From time to time, make sure to check if your hard disk is full
df -h
To see current node logs use command:
tail -F log_stdout_node1.log
Ctrl+C to stop it
1. Visit Web App
https://app.idena.io
a) Create Account if you are new, or
b) Sign in if you allready have account, or
c) If you have Idena Desktop App, click on "Backup private key" and use that to sign in to Web App.
2. If you are creating new account
- Follow steps which are guiding you
- Save password and private key that you have made in this process
- It's easiest to save them in "Google Keep" app if you have Google account.
3. Sign in
4. Go to "Training validation"
- Try one of available options for training.
https://app.idena.io
a) Create Account if you are new, or
b) Sign in if you allready have account, or
c) If you have Idena Desktop App, click on "Backup private key" and use that to sign in to Web App.
2. If you are creating new account
- Follow steps which are guiding you
- Save password and private key that you have made in this process
- It's easiest to save them in "Google Keep" app if you have Google account.
3. Sign in
4. Go to "Training validation"
- Try one of available options for training.
Visit and READ Idena website
Download the App
Links:
Before you start asking questions, make sure you read FAQ general section on website. Try to read it with understanding.
Also, read instalation and troubleshooting FAQ before asking questions about instalation and configuration.
Explorer can show you Identities, addresses, transactions, real information about rewards, validation results, flips and so much more.
Follow official Idena Announcements channel on Telegram
Community run Discord server
Bitcointalk Forum thread
Read about Idena's concept in Idena Concept Paper
If you want to make a Idena presentation to someone, feel free to use Pitch Deck
Stay in the loop and follow Idena's Medium page
Buy or Sell Idena coins:
qTrade: https://qtrade.io/market/IDNA_BTC
Hotbit: https://www.hotbit.io/exchange?symbol=IDNA_BTC
Coins emission:
Block reward: 6 iDNA
Blocks per minute: 3
Maximum number of blocks per day: 4,320
Mining cap per day: 25,920 iDNA (50%)
Accumulating fund per day for validation session: 25,920 iDNA (50%)
Total daily emmision: 51,840 iDNA
Download the App
Links:
Before you start asking questions, make sure you read FAQ general section on website. Try to read it with understanding.
Also, read instalation and troubleshooting FAQ before asking questions about instalation and configuration.
Explorer can show you Identities, addresses, transactions, real information about rewards, validation results, flips and so much more.
Follow official Idena Announcements channel on Telegram
Community run Discord server
Bitcointalk Forum thread
Read about Idena's concept in Idena Concept Paper
If you want to make a Idena presentation to someone, feel free to use Pitch Deck
Stay in the loop and follow Idena's Medium page
Buy or Sell Idena coins:
qTrade: https://qtrade.io/market/IDNA_BTC
Hotbit: https://www.hotbit.io/exchange?symbol=IDNA_BTC
Coins emission:
Block reward: 6 iDNA
Blocks per minute: 3
Maximum number of blocks per day: 4,320
Mining cap per day: 25,920 iDNA (50%)
Accumulating fund per day for validation session: 25,920 iDNA (50%)
Total daily emmision: 51,840 iDNA
PC requirements for running Idena:
- Processor: 64-bit, 2 cores
- Memory: 4GB
- Hard disk: 100GB (not right from start, but it's good to have)
- Operating system: Windows 7 or newer (64-bit)
- Internet connection: Flat internet tariff, more than 600GB of monthly traffic
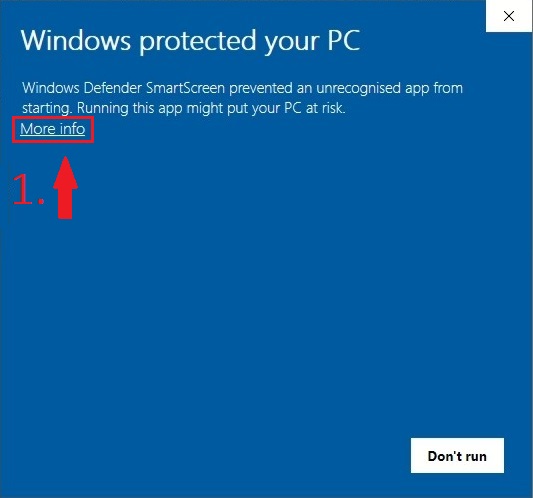
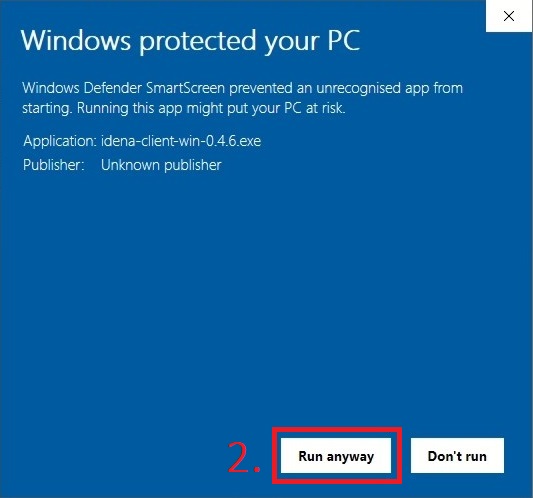
Having trouble running Idena instalation on Windows?
Check your security 3rd party antivirus/firewall software, maybe something is blocking installation. Try to disable them prior to running Idena installation. If that helps try to add Idena to the exeptions list so the security software does not block Idena.
From security standpoint, If you are concerned if the installation is clean, feel free to check source code on Github and build installation yourself. So far, no one confirmed any problems.
PC requirements for running Idena:
- Processor: 64-bit, 2 core (4 cores recomended)
- Memory: 4GB
- Hard disk: 100GB
- Operating system: Debian based linux distribution. For this video I've used Ubuntu 18.04 64-bit, please let us know, which distribution also worked for you.
- Internet connection: Flat internet tariff, more than 600GB of monthly traffic
Tested so far:
Lubuntu 16.04 - does not work
Ubuntu 18.04 - works
Ubuntu 19.01 - works
You can also try to install Idena Desktop App from terminal (just use newest version of file):
wget https://github.com/idena-network/idena-desktop/releases/download/v0.21.2/idena-client-linux-0.21.2.deb
sudo dpkg -i idena-client-linux-0.21.2.deb
or try if above doesn't work:
sudo dpkg-deb -xv idena-client-linux-0.21.2.deb /
For Idena on Debian 10 Buster, you need to make 4755 permission for crome-sandbox in opt/idena directory. Or put --no-sandbox in the shortcut for Idena.
What is private key? Private key is password that holds information about your Idena address. With that, by posessing it you are in controll of that address, identity and coins that are on that address.
Most important thing after you install Idena is to backup your private key and store it somewhere safely. By making backup of your private key, your Idena coins and identity will be safe, even if your computer dies. You can make backup as file (nodekey) or as private key (open nodekey with notepad and copy it somewhere safe).
Nodekey default location is:
You can copy it and paste this location for easy use. Take a look at this video to see how to do this.
Where to safely backup your private key?
I use portable eddition of opensource password manager KeePass which I store in a cloud. For cloud provider, you can choose provider (Google, Dropbox, Yandex...) you trust the most, or even two providers if you are feeling paranoid :)
You can also write your private key on a paper and put it in some safe.
Most important thing after you install Idena is to backup your private key and store it somewhere safely. By making backup of your private key, your Idena coins and identity will be safe, even if your computer dies. You can make backup as file (nodekey) or as private key (open nodekey with notepad and copy it somewhere safe).
Nodekey default location is:
%appdata%\Idena\node\datadir\keystoreYou can copy it and paste this location for easy use. Take a look at this video to see how to do this.
Where to safely backup your private key?
I use portable eddition of opensource password manager KeePass which I store in a cloud. For cloud provider, you can choose provider (Google, Dropbox, Yandex...) you trust the most, or even two providers if you are feeling paranoid :)
You can also write your private key on a paper and put it in some safe.
What is private key? Private key is password that holds information about your Idena address. With that, by posessing it you are in controll of that address, identity and coins that are on that address.
Most important thing after you install Idena is to backup your private key and store it somewhere safely. By making backup of your private key, your Idena coins and identity will be safe, even if your computer dies. You can make backup as file (nodekey) or as private key (open nodekey with Text Editor and copy it somewhere safe).
Nodekey default location is:
Take a look at this video to see how to open this location.
Where to safely backup your private key?
I use portable eddition of opensource password manager KeePass which I store in a cloud. For cloud provider, you can choose provider (iCloud Drive, Google, Dropbox, Yandex...) you trust the most, or even two providers if you are feeling paranoid :)
You can also write your private key on a paper and put it in some safe.
macOS Catalina 10.15 minimum
Most important thing after you install Idena is to backup your private key and store it somewhere safely. By making backup of your private key, your Idena coins and identity will be safe, even if your computer dies. You can make backup as file (nodekey) or as private key (open nodekey with Text Editor and copy it somewhere safe).
Nodekey default location is:
~/Library/Application\ Support/Idena/node/datadir/keystoreTake a look at this video to see how to open this location.
Where to safely backup your private key?
I use portable eddition of opensource password manager KeePass which I store in a cloud. For cloud provider, you can choose provider (iCloud Drive, Google, Dropbox, Yandex...) you trust the most, or even two providers if you are feeling paranoid :)
You can also write your private key on a paper and put it in some safe.
macOS Catalina 10.15 minimum
What is private key? Private key is password that holds information about your Idena address. With that, by posessing it you are in controll of that address, identity and coins that are on that address.
Most important thing after you install Idena is to backup your private key and store it somewhere safely. By making backup of your private key, your Idena coins and identity will be safe, even if your computer dies. You can make backup as file (nodekey) or as private key (open nodekey with any text editor and copy it somewhere safe).
Nodekey default location is:
Take a look at this video to see how to do this.
Where to safely backup your private key?
I use portable eddition of opensource password manager KeePass which I store in a cloud. For cloud provider, you can choose provider (Google, Dropbox, Yandex...) you trust the most, or even two providers if you are feeling paranoid :)
You can also write your private key on a paper and put it in some safe.
Most important thing after you install Idena is to backup your private key and store it somewhere safely. By making backup of your private key, your Idena coins and identity will be safe, even if your computer dies. You can make backup as file (nodekey) or as private key (open nodekey with any text editor and copy it somewhere safe).
Nodekey default location is:
~/.config/Idena/node/datadir/keystore/nodekeyTake a look at this video to see how to do this.
Where to safely backup your private key?
I use portable eddition of opensource password manager KeePass which I store in a cloud. For cloud provider, you can choose provider (Google, Dropbox, Yandex...) you trust the most, or even two providers if you are feeling paranoid :)
You can also write your private key on a paper and put it in some safe.
There are multiple ways for you to try and get an invitation for Idena. Check on Idena website to find out when the next validation is going to happen, you can see exact date and time in your local time zone. You have untill then to try and get an invite if you want to participate in the next validation.
First of all, ask yourself can you organize yourself so you can have time to do next three validations? That is the most important thing you can do in order to convince someone you don't know, to trust you with his invitation code. Person who gives you invitation will receive reward if you successfuly pass three consecutive validations. So, Idena members are looking to give their invitations to person who is showing genuine interest for Idena and seem reliable.
Some members will try and chat a bit with you to try and see if you are reliable. Can you organize yourself not to forget about validation? Will you able to make flips? Will you bail out after first validation?
A plus is if you are native english speaker. If you are not, and you can comunicate good enough, that is also great. If you come in channels and just copy paste "Invite please", "Need invite" or something simmilar, don't expect to get invitation just based on that.
Try your best to educate yourself about Idena, validation and flips. Make sure you practice flips. Members will most probbably ask you some questions to see if you have read any info about Idena. Some will ask to do some logical easy and funny task so you prove yourself that you are logical person and commited.
Basically it comes to it, that you should be a normal person.
Can you make effort if validation is on working day? Is exact validation time a problem for you? If validation happens during work hours, can you make 20 minutes break to do validation?
If you are out of the house and away from your pc, you can use Idena Web App and do validation from your mobile device.
Idena members are also cautious to give out invitations freely because there are:
- Many fake accounts, made to ask for invites and to waste them on purpose. That way network does not grow, so rewards stay nearly the same in next epoch (for current members).
- People who are training their AI programs and waste invites, so they can try to collect bounty.
- Random people who just stumbled on this project and ask for code, you give it to them, after they read more, and decide, well this is not for them and they bail out on validation.
- People who can't pass validation. Either they have some computer problem, or they realy don't understand flip logic, or behind some firewall that produces crazy results.
Here are places where you can ask for invitation code:
 Contact me on Telegram so I can put you on the invitation waiting list.
Contact me on Telegram so I can put you on the invitation waiting list.
Comunity Discord server - this place is organised and good place to ask for invitations, it includes invitation offers channal where you can ask for an invitation.
Idena thread on Bitcointalk forum - great place to ask for invitations if you have user account with good reputation.
Last but not least, here is great article on what is important to know to get invitation
https://medium.com/idena/how-to-get-idena-invitation-easy-and-fast-ec1faace5cc7
First of all, ask yourself can you organize yourself so you can have time to do next three validations? That is the most important thing you can do in order to convince someone you don't know, to trust you with his invitation code. Person who gives you invitation will receive reward if you successfuly pass three consecutive validations. So, Idena members are looking to give their invitations to person who is showing genuine interest for Idena and seem reliable.
Some members will try and chat a bit with you to try and see if you are reliable. Can you organize yourself not to forget about validation? Will you able to make flips? Will you bail out after first validation?
A plus is if you are native english speaker. If you are not, and you can comunicate good enough, that is also great. If you come in channels and just copy paste "Invite please", "Need invite" or something simmilar, don't expect to get invitation just based on that.
Try your best to educate yourself about Idena, validation and flips. Make sure you practice flips. Members will most probbably ask you some questions to see if you have read any info about Idena. Some will ask to do some logical easy and funny task so you prove yourself that you are logical person and commited.
Basically it comes to it, that you should be a normal person.
Can you make effort if validation is on working day? Is exact validation time a problem for you? If validation happens during work hours, can you make 20 minutes break to do validation?
If you are out of the house and away from your pc, you can use Idena Web App and do validation from your mobile device.
Idena members are also cautious to give out invitations freely because there are:
- Many fake accounts, made to ask for invites and to waste them on purpose. That way network does not grow, so rewards stay nearly the same in next epoch (for current members).
- People who are training their AI programs and waste invites, so they can try to collect bounty.
- Random people who just stumbled on this project and ask for code, you give it to them, after they read more, and decide, well this is not for them and they bail out on validation.
- People who can't pass validation. Either they have some computer problem, or they realy don't understand flip logic, or behind some firewall that produces crazy results.
Here are places where you can ask for invitation code:
Contact me on Telegram so I can put you on the invitation waiting list.Comunity Discord server - this place is organised and good place to ask for invitations, it includes invitation offers channal where you can ask for an invitation.
Idena thread on Bitcointalk forum - great place to ask for invitations if you have user account with good reputation.
Last but not least, here is great article on what is important to know to get invitation
https://medium.com/idena/how-to-get-idena-invitation-easy-and-fast-ec1faace5cc7
It is recommended to go to through pre-validation check of your technical setup of Idena Desktop App and node. It will be a lot of information, try to do things that seem easy enough for you to do. Please consider these few advices:
1. Time synchronisation
Time synchronisation is of great importance for successful validation. Experience tells me that Windows users are affected mostly with time synchronisation issue. Thing is, windows has built-in time synchronisation which synchronises time once in 7 days. So it is very likely that you will be out of sync to some extent on validation day. To check how much in sync your PC is right now, visit time.is website.
Problem:
What can out-of-sync cause during validation? It can fool Idena app to show you wrong time during short session. You can have 16 seconds displayed as remaining time, but in fact if your PC time is out of sync for let's say 19 seconds, you have already missed the time to submit your answers, so you can fail validation short session with result "Late Submission".
Solution:
Install free program that can sync your time more often. You can download it by visiting website NetTime, or download it directly from this link. Allow it to be installed as a service so it runs automatically in the background.
2. Internet connection
Idena at home:
If you run node in a home environment, there is whole lot of things to consider that can cause problems:
- Router quality: Did your internet start disconnecting from time to time while using idena? Many home routers are low quality and can't handle this kind of traffic and connections that Idena is making. Regular cisco will work like a charm. If you replace your current router that is disconnecting with some regular cisco or mikrotik, you won't have problems. You can restart your router one day before validation so it clears its cache if it has any, so it can serve you as good as it can on validation day.
There are four category of routers for Idena:
- weak (can not handle connections even for basic synchronisation)
- medium (can synchronize, but under validation higher load, they start making problems)
- normal (work good even for validation)
- strong (can run multiple idena nodes)
Biggest problem are medium strength routers which do not show a sign of failure before validation, and we do not have a way to grade all router hardware by specifications.
- Wi-Fi: Are you running Idena on laptop over Wi-Fi? How good is your Wi-Fi? Since Wi-Fi is something unpredictable, if you know from experience that your wifi is sometimes unstable, it is recommended to hook up a lan cable during validation session so you avoid potential problems.
- Other people in house and running programs: Are you running other programs like torrent or are you on a shared internet? Turn off all other things that are using internet during validation time, and ask your roommates/family members not to use internet during validation time (It's just 15min once in a 18 days).
- Internet speed: I don't have exact data but 2mbps of upload speed would be questionable recommended minimum for validation of one Idena on that internet using --profile=lowpower option. See how to setup that option on this video (read video description).
3. Hardware resources and performance
Hardware requirements is complicated subject as there are many possible setups and pc hardware on which you can run full Idena Desktop App or just node. As I don't have much experience with all devices (like RaspberryPi or Mac's) and operating systems like all possible Linux distributions, I will try to give general suggestions.
CPU power: validation is more cpu intensive than in-between validation node mining. So if your mining is working ok, that does not mean that your validation will be fine if you limit your CPU for Idena in some way. If you use Idena on laptop on windows and connect to it remotely, don't close lid of your laptop as it will disable graphics card and your CPU will maybe have problem to deal with all that needs to be done and possibly go out of sync during validation. Also some PC's/Operating systems disable graphics card if you don't have monitor attached, that can also cause issues in getting all computational load on CPU. I would say Intel i3 or simmilar will serve just fine.
RAM memory: I have noticed that node starts by using 200MB of RAM. Over time, if you don't restart it, it consumes more and more memory. I have seen it go up to 1.5 GB after days of non stop activity. This is very problematic for VPS or PC's that have limited ammount of RAM. If you have swap file(virtual memory on hard disk), it will help but not for long. After some time I guess CPU has to deal with node and ram and swap and node starts to go offline from time to time. It is very recommended to restart your node one day before validation. Not right before validation as then load on network is high and if you are not lucky, you might not connect to peers fast enough. After you restart node, it will go to using 200-500MB of RAM and it will be in best condition for validation.
Please don't use VPS's with Windows and 2GB of ram, you will maybe pass one validation, but will fail next for sure. For VPS with Windows, 4GB is minimum for normal funcioning for you to be safe and not fail validation.
Feel free to contact me on Telegram or by email if you have more suggestions on how to make this text better and help Idena community out.
1. Time synchronisation
Time synchronisation is of great importance for successful validation. Experience tells me that Windows users are affected mostly with time synchronisation issue. Thing is, windows has built-in time synchronisation which synchronises time once in 7 days. So it is very likely that you will be out of sync to some extent on validation day. To check how much in sync your PC is right now, visit time.is website.
Problem:
What can out-of-sync cause during validation? It can fool Idena app to show you wrong time during short session. You can have 16 seconds displayed as remaining time, but in fact if your PC time is out of sync for let's say 19 seconds, you have already missed the time to submit your answers, so you can fail validation short session with result "Late Submission".
Solution:
Install free program that can sync your time more often. You can download it by visiting website NetTime, or download it directly from this link. Allow it to be installed as a service so it runs automatically in the background.
2. Internet connection
Idena at home:
If you run node in a home environment, there is whole lot of things to consider that can cause problems:
- Router quality: Did your internet start disconnecting from time to time while using idena? Many home routers are low quality and can't handle this kind of traffic and connections that Idena is making. Regular cisco will work like a charm. If you replace your current router that is disconnecting with some regular cisco or mikrotik, you won't have problems. You can restart your router one day before validation so it clears its cache if it has any, so it can serve you as good as it can on validation day.
There are four category of routers for Idena:
- weak (can not handle connections even for basic synchronisation)
- medium (can synchronize, but under validation higher load, they start making problems)
- normal (work good even for validation)
- strong (can run multiple idena nodes)
Biggest problem are medium strength routers which do not show a sign of failure before validation, and we do not have a way to grade all router hardware by specifications.
- Wi-Fi: Are you running Idena on laptop over Wi-Fi? How good is your Wi-Fi? Since Wi-Fi is something unpredictable, if you know from experience that your wifi is sometimes unstable, it is recommended to hook up a lan cable during validation session so you avoid potential problems.
- Other people in house and running programs: Are you running other programs like torrent or are you on a shared internet? Turn off all other things that are using internet during validation time, and ask your roommates/family members not to use internet during validation time (It's just 15min once in a 18 days).
- Internet speed: I don't have exact data but 2mbps of upload speed would be questionable recommended minimum for validation of one Idena on that internet using --profile=lowpower option. See how to setup that option on this video (read video description).
3. Hardware resources and performance
Hardware requirements is complicated subject as there are many possible setups and pc hardware on which you can run full Idena Desktop App or just node. As I don't have much experience with all devices (like RaspberryPi or Mac's) and operating systems like all possible Linux distributions, I will try to give general suggestions.
CPU power: validation is more cpu intensive than in-between validation node mining. So if your mining is working ok, that does not mean that your validation will be fine if you limit your CPU for Idena in some way. If you use Idena on laptop on windows and connect to it remotely, don't close lid of your laptop as it will disable graphics card and your CPU will maybe have problem to deal with all that needs to be done and possibly go out of sync during validation. Also some PC's/Operating systems disable graphics card if you don't have monitor attached, that can also cause issues in getting all computational load on CPU. I would say Intel i3 or simmilar will serve just fine.
RAM memory: I have noticed that node starts by using 200MB of RAM. Over time, if you don't restart it, it consumes more and more memory. I have seen it go up to 1.5 GB after days of non stop activity. This is very problematic for VPS or PC's that have limited ammount of RAM. If you have swap file(virtual memory on hard disk), it will help but not for long. After some time I guess CPU has to deal with node and ram and swap and node starts to go offline from time to time. It is very recommended to restart your node one day before validation. Not right before validation as then load on network is high and if you are not lucky, you might not connect to peers fast enough. After you restart node, it will go to using 200-500MB of RAM and it will be in best condition for validation.
Please don't use VPS's with Windows and 2GB of ram, you will maybe pass one validation, but will fail next for sure. For VPS with Windows, 4GB is minimum for normal funcioning for you to be safe and not fail validation.
You can use htop command on your VPS to see current available ram memory, see the picture below:
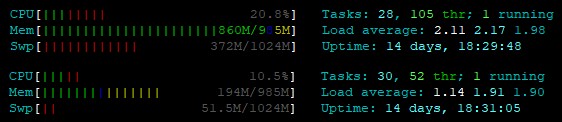
Result of htop command, before and after node restart
Result of htop command, before and after node restart
Feel free to contact me on Telegram or by email if you have more suggestions on how to make this text better and help Idena community out.
If your Desktop App worked normal and this happened after sudden computer restart or something:
1. Go here:
On Windows
On Linux
2. Delete settings.json file and Quit and start Idena again
your file probably got corrupted because of sudden restart. If just deleting settings.json does not help, rename all .json files there and restart Idena App.
If it's all white the first time you have started (using Windows), then read following.
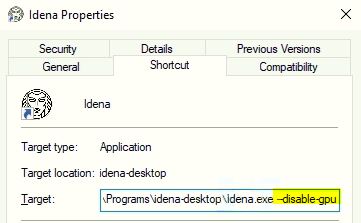
Idena app uses GPU acceleration to render its graphics content. If for some reason it can't access GPU to render its view, It will show all white screen. You can try to solve this by running it with "--disable-gpu" parameter.
This is how I managed to set it up in Windows:
1. Right click on "Idena" shortcut, choose "Properties"
2. In the "Target" field, add " --disable-gpu" at the end, click OK
1. Go here:
On Windows
%appdata%\IdenaOn Linux
~/.config/Idena (go to home directory, press Ctrl+H to show hidden directories)2. Delete settings.json file and Quit and start Idena again
your file probably got corrupted because of sudden restart. If just deleting settings.json does not help, rename all .json files there and restart Idena App.
If it's all white the first time you have started (using Windows), then read following.
Idena app uses GPU acceleration to render its graphics content. If for some reason it can't access GPU to render its view, It will show all white screen. You can try to solve this by running it with "--disable-gpu" parameter.
This is how I managed to set it up in Windows:
1. Right click on "Idena" shortcut, choose "Properties"
2. In the "Target" field, add " --disable-gpu" at the end, click OK
For Idena on Debian 10 Buster
You need to make 4755 permission for crome-sandbox in opt/idena directory.
Or put --no-sandbox in the shortcut for Idena.
(thanks to Difermo for the fix)
Mint
wget https://github.com/idena-network/idena-desktop/releases/download/v0.21.2/idena-client-linux-0.21.2.deb
sudo dpkg -i idena-client-linux-0.21.2.deb
or try if above doesn't work:
sudo dpkg-deb -xv idena-client-linux-0.21.2.deb /
You need to make 4755 permission for crome-sandbox in opt/idena directory.
Or put --no-sandbox in the shortcut for Idena.
(thanks to Difermo for the fix)
Mint
wget https://github.com/idena-network/idena-desktop/releases/download/v0.21.2/idena-client-linux-0.21.2.deb
sudo dpkg -i idena-client-linux-0.21.2.deb
or try if above doesn't work:
sudo dpkg-deb -xv idena-client-linux-0.21.2.deb /
1. Oracle-secured OTC escrow provider
I would love it if someone builds an oracle-secured OTC escrow provider for every major Cryptocurrency. Maybe even attractive for shitcoins that are nowhere listed yet. The oracle gets funded by buyer and seller with security and thereafter witnesses the OTC transaction manually by looking it up at blockexplorers. If the trade did happen, both party get refunded their security. If one side plays foul, its security gets transfered to the victim. Oracle decides. Should be fun. Maybe there could even be a liquidity provider paying out the transaction instantly secured by idena. I just dont know if oracles will be cheap enough for such buisiness with small transactions.
I would love it if someone builds an oracle-secured OTC escrow provider for every major Cryptocurrency. Maybe even attractive for shitcoins that are nowhere listed yet. The oracle gets funded by buyer and seller with security and thereafter witnesses the OTC transaction manually by looking it up at blockexplorers. If the trade did happen, both party get refunded their security. If one side plays foul, its security gets transfered to the victim. Oracle decides. Should be fun. Maybe there could even be a liquidity provider paying out the transaction instantly secured by idena. I just dont know if oracles will be cheap enough for such buisiness with small transactions.
Fix corrupted indenachain on vps with Idena manager broken db idenachain corrupted idena manager vps
If you have used my guide to setup node on VPS. Then you can use this script to fix your node if it's got corrupted chain database
wget https://raw.githubusercontent.com/rioda-org/idena/main/fixdb_idena_manager.sh && bash fixdb_idena_manager.sh
wget https://raw.githubusercontent.com/rioda-org/idena/main/fixdb_idena_manager.sh && bash fixdb_idena_manager.sh
Step by step instructions on how to run Idena node on Raspberry Pi 4 + m.2 drive:
https://medium.com/@viscousmucus/running-an-idena-node-on-a-raspberry-pi-4-1e595898bd61
Script for Idena node setup on 64-bit Ubuntu server:
https://github.com/rioda-org/idena/blob/main/raspberry_pi/build_for_64bit
Another step by step instruction:
https://study.5dimn.com/?p=709
Link for binary downloads:
https://drive.google.com/drive/folders/1E57YG1C1FWkFuxbD3rY9CPvrJWQlEc-N?usp=sharing
https://medium.com/@viscousmucus/running-an-idena-node-on-a-raspberry-pi-4-1e595898bd61
Script for Idena node setup on 64-bit Ubuntu server:
https://github.com/rioda-org/idena/blob/main/raspberry_pi/build_for_64bit
Another step by step instruction:
https://study.5dimn.com/?p=709
Link for binary downloads:
https://drive.google.com/drive/folders/1E57YG1C1FWkFuxbD3rY9CPvrJWQlEc-N?usp=sharing
wget https://raw.githubusercontent.com/rioda-org/idena/main/update.sh && bash update.sh
Insert your own API key and adjust the address/port if needed. Maybe wait like 10 seconds to let the node start before running this though.
curl 'http://127.0.0.1:9009/' -H 'Content-Type: application/json' --data '{"method":"dna_becomeOnline","params":[{}],"id":1,"key":"YOUR API KEY"}'
curl 'http://127.0.0.1:9009/' -H 'Content-Type: application/json' --data '{"method":"dna_becomeOnline","params":[{}],"id":1,"key":"YOUR API KEY"}'
Clean reinstalation of your Idena app and node will solve 99% of every problem that you come acros. Follow next steps:
1. Backup your nodekey file from %appdata%\Idena\node\datadir\keystore\nodekey
2. Uninstall Idena
3. Delete folders:
%appdata%\Idena
%userprofile%\AppData\Local\Programs\idena-desktop
4. Install fresh new version from idena website and restore your nodekey file
1. Backup your nodekey file from %appdata%\Idena\node\datadir\keystore\nodekey
2. Uninstall Idena
3. Delete folders:
%appdata%\Idena
%userprofile%\AppData\Local\Programs\idena-desktop
4. Install fresh new version from idena website and restore your nodekey file
1. Go to %appdata%\Idena
2. Open up "invites.json" file, look around, you will find it
2. Open up "invites.json" file, look around, you will find it
Yes it is possible, some people are faster than others in solving flips. In the long run, the question is, is it worth it?
You are risking failing validations if you get some flips that are hard to solve. You are under pressure to preform faster, prone to wrong answers. In the long run, wrong answers provide you with lower score keeping you from getting invitation code for distribution. You are obligated to create twice as much flips.
You are risking failing validations if you get some flips that are hard to solve. You are under pressure to preform faster, prone to wrong answers. In the long run, wrong answers provide you with lower score keeping you from getting invitation code for distribution. You are obligated to create twice as much flips.
1. Open up Idena Web App using Firefox/Chrome/Edge. Brave browser can cause problems. Others remain to be tested.
2. Login to your account, or create new. If you are creating new it is important to save all your passwords, keys and addresses. Easiest option is to save it to textual file on Google Drive.
3. After you login, chose option 2, Enter your Api key.
4. Connect to your node
Shared node URL: http://localhost:9119
Api key: find it in this location: %appdata%/Idena/node/datadir/
Open api.key file with notepad.
2. Login to your account, or create new. If you are creating new it is important to save all your passwords, keys and addresses. Easiest option is to save it to textual file on Google Drive.
3. After you login, chose option 2, Enter your Api key.
4. Connect to your node
Shared node URL: http://localhost:9119
Api key: find it in this location: %appdata%/Idena/node/datadir/
Open api.key file with notepad.
1. Go to Settings > Node > Turn off "Run built-in node"
2. Go to node location
a) for Windows, it's folder "%appdata%/Idena/node"
- open any folder and copy paste that line like this
- hit enter
b) for Linux, it's ~/.config/Idena/node
c) for MacOS, watch this video to show you how to get to this location
3. Delete "idena-go"
4. Rename "new-idena-go" to "idena-go"
5. Go back to Settings > Node > Turn on "Run built-in node"
2. Go to node location
a) for Windows, it's folder "%appdata%/Idena/node"
- open any folder and copy paste that line like this
- hit enter
b) for Linux, it's ~/.config/Idena/node
c) for MacOS, watch this video to show you how to get to this location
3. Delete "idena-go"
4. Rename "new-idena-go" to "idena-go"
5. Go back to Settings > Node > Turn on "Run built-in node"
Import key does not work import key
If for some reason Import key option does not work, here is workaround
1. Close Idena App
2. Visit https://devkodev.github.io/IdenaDevTools/
3. Use decrypt key option to get private key
4. Go to location
5. Open
6. Start Idena App
1. Close Idena App
2. Visit https://devkodev.github.io/IdenaDevTools/
3. Use decrypt key option to get private key
4. Go to location
%appdata%/idena/node/datadir/keystore/5. Open
nodekey file using notepad and save private key that you got in previous step6. Start Idena App
Web App web app
Web App link
For security reasons, disable spellchecking features or add-ons for Web App page if possible.
- You need to rent a node for any validation other than first. First is free. Validation does not work on restricted connection.
- If you are using Windows OS, it is important to install free software NetTime which will keep your clock in perfect synchronization which is important for validation.
- Make sure you turn off every other application that uses the internet.
- Do not run Idena Desktop App with node during validation if you have bad internet.
- Do not use JavaScript blocking extensions for your browser (NoScript, PrivacyBadger, Ghostery), Brave browser has built in blockers and will cause problem if you don't know how to configure it.
- Do not use browser with auto translate option
- Sign in to Web App 6 minutes before validation starts and keep that browser window active, don't navigate to other tab (if you are on mobile) or else you will fail validation with "Late submission" result.
For security reasons, disable spellchecking features or add-ons for Web App page if possible.
Desktop App desktop app
- For Desktop App, you need unlimited internet. Desktop App uses about 50 GB monthly. You need to sync your node 4 hours before validation.
- Check your internet connection quality here. If your connection is graded A or B, you have a good connection. If it's C or worse, it is bad. If you are connected via Wi-Fi, try connecting using LAN cable and check connection again. If your connection is still bad, you MUST use Web App for validation.
- If you are using Windows OS, you must install free software NetTime which will keep your clock in perfect synchronization which is important for validation.
- Turn off any other applications which are using the internet.
- Start your Idena Desktop App two hours before validation starts, so it can synchronize with the network and keep a stable connection.
What is delegation? delegation
Delegation allows you to transfer your mining power over to someone you can trust. Great example is a family of 4 where all are doing validations, but it makes no sense to run 4 nodes for 21 days in-between validations, for mining purposes. What they can do is, 3 members can delegate mining to first family member and they need to keep only 1 pc/node up and running.
https://www.top-password.com/blog/automatically-sync-windows-time-more-often-than-default/
1. Quit the App
2. Move the node folder (%appdata%/idena/node) to D:\ or wherever you want
3. Run the node manually, node/idena-go.exe
4. Run App and connect it to the running node
Settings > Node > Connect to remote node, find api key in node/datadir/api.key file
2. Move the node folder (%appdata%/idena/node) to D:\ or wherever you want
3. Run the node manually, node/idena-go.exe
4. Run App and connect it to the running node
Settings > Node > Connect to remote node, find api key in node/datadir/api.key file
VPS is considered as advanced setup. Basically this is setup on linux, so you have to know some basic linux stuff. There is no graphical interface, which makes it even more dificult for linux begginers.
1. Get two months free credits on one of the following VPS providers:
Register at Hetzner
Register at Vultr
Register at Digital Ocean
Chose VM instance that has minimum 2GB of ram memory.
2. Once you register account, you must enter your credit/debit card.
3. Chose Ubuntu 18.04 x64 as Operating system for your server.
4. Under your provider console you'll find your server IP and password for root user, you need this to connect to your server from your PC. Let's presume you are running Windows on your home PC.
5. Download Putty, it's a free program that connects to your server, and you can type in commands to deal with idena node and stuff.
6. In Putty, connect to your servers IP address, just enter address in first screen of putty and hit "Open", it'll ask you to import some key, confirm it.
7. Login as user root and use password from vultr console. You can copy paste it since its complicated. When you right click in Putty, password will be allready pasted although it won't show any input, just hit enter after that.
8. Now that we are successfuly loged into server, these are commands that you need to copy paste in Putty
a. cd /home && wget https://github.com/idena-network/idena-go/releases/download/v1.1.1/idena-node-linux-1.1.1
(this gets us in home directory and downloads idena node)
b. mv idena-node-linux-1.1.1 idena-go
(this will rename our downloaded node file to idena-go so it's easier for us to use it)
c. chmod +x idena-go
(this gives idena node file, permision to execute, a linux security measure)
d. screen ./idena-go
(this runs idena node in separate screen, If we dont run it this way, you would have to leave your Putty window open all the time, as well as your PC)
e.
(this disconects us from that virtual screen where idena node is running but leaves it running in background, so we can exit Putty without stopping idena node)
f. nano /home/datadir/api.key
copy that code that you get and save it somewhere on PC
(nano is like notepad for linux, we use it to open api.key file, you need api.key which is password for accessing your node so you can connect from idena app on your PC)
9. Now, close Putty and open it up so we can save connection and tunnel settings. Setup tunnel for connection as showed in this picture
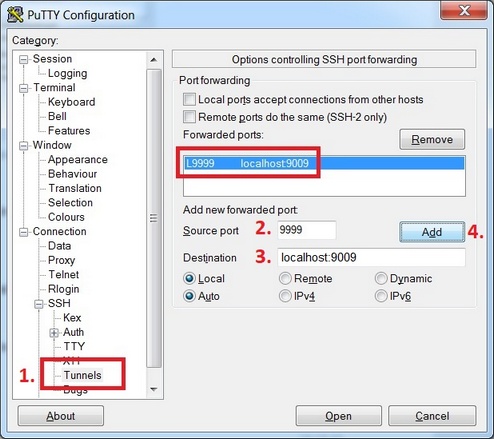
In source enter:
In destination enter:
After you click Add, tunnel is saved. Next step is to save your IP address and connection. Go back to first option on top "Session" in Putty, in Host Name enter your vps IP address as before, in Saved Sessions enter name "vps connection" and press "Save button".
Now we have saved connection details with tunnel, so next time you open Putty you can doubleclick on saved "vps connection" and your login to vps will appear.
10. Connect to server using putty as before, using root/password... but now we have node running and tunneled connection
11. Configure Idena client to use node on your VPS. Open idena on PC, go to settings>node turn off "Run built-in node", turn on "Connect to remote node", set:
Node address:
Node api key:
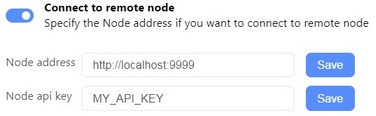
Save both settings
12. Now check if you have some idena address by going to My Idena, you'll have some new address(robot) that is not yours. This is normal because you've run new node that generated new address.
13. Now you can transfer your private key/nodekey/identity to the VPS. We must find it on your PC, go to
(best if you copy paste this in some folders address) there you will find nodekey file. Open it with notepad and copy it.
ALSO, IMPORTANT, BACKUP THIS, THIS IS YOUR PRIVATE KEY, DON'T SHARE IT WITH ANYONE.
14. Now we must put it on VPS. In Putty, run nano to edit nodekey file on vps so you can paste it there
nano /home/datadir/keystore/nodekey
this will open current private key on VPS, you must delete it and paste your from PC. Make sure you don't have any unnessessary blank spaces or new lines. After paste, just exit nano Ctrl+X when it asks you to save, save it by pressing Y and confirm file name by pressing Enter. Now you have transfered your identity to VPS.
15. We must restart node on VPS so it runs with new key/identity
screen -r - return to running node
cd /home - change directory from current /root to the /home where the node is
screen -d -m ./idena-go - run it again in a detached screen
Now when you go to client, you should see your identity/address/robot.
Now, you need to connect Putty every time you want to open Idena client on PC (when making flips, doing validation, sending coins etc...)
But node runs and mines on VPS with or without Idena client.
So... this setup might take some time, make sure to check if mining is on, after all that you've done.
Adding a Swap file (virtual memory)
If you are running vps with a 1GB memory, it would be wise to enable swap (virtual memory) in case your vps runs low on memory
Enter this command to make additional 1GB swap memmory:
sudo fallocate -l 1G /swapfile2 && sudo chmod 600 /swapfile2 && sudo mkswap /swapfile2 && sudo swapon /swapfile2 && echo '/swapfile2 none swap sw 0 0' | sudo tee -a /etc/fstab
Pre-validation checkup
As node works, over time it starts to take more and more memory of the system. On the start it uses about 200mb of RAM memory. If it runs for a week or so, it can reach up to 700mb. It is very recomended to restart your node one day before validation so it clears up RAM memory so your validation runs without problems.
You can restart node with commands:
killall screen
cd /home
screen -d -m ./idena-go
Idena manager
Also take a look at comunity made script Idena Manager, this is all in one automated script to setup, run and update your node:
https://gitlab.com/crackowich/idena-manager
1. Get two months free credits on one of the following VPS providers:
Register at Hetzner
Register at Vultr
Register at Digital Ocean
Chose VM instance that has minimum 2GB of ram memory.
2. Once you register account, you must enter your credit/debit card.
3. Chose Ubuntu 18.04 x64 as Operating system for your server.
4. Under your provider console you'll find your server IP and password for root user, you need this to connect to your server from your PC. Let's presume you are running Windows on your home PC.
5. Download Putty, it's a free program that connects to your server, and you can type in commands to deal with idena node and stuff.
6. In Putty, connect to your servers IP address, just enter address in first screen of putty and hit "Open", it'll ask you to import some key, confirm it.
7. Login as user root and use password from vultr console. You can copy paste it since its complicated. When you right click in Putty, password will be allready pasted although it won't show any input, just hit enter after that.
8. Now that we are successfuly loged into server, these are commands that you need to copy paste in Putty
a. cd /home && wget https://github.com/idena-network/idena-go/releases/download/v1.1.1/idena-node-linux-1.1.1
(this gets us in home directory and downloads idena node)
b. mv idena-node-linux-1.1.1 idena-go
(this will rename our downloaded node file to idena-go so it's easier for us to use it)
c. chmod +x idena-go
(this gives idena node file, permision to execute, a linux security measure)
d. screen ./idena-go
(this runs idena node in separate screen, If we dont run it this way, you would have to leave your Putty window open all the time, as well as your PC)
e.
Ctrl+A+D to exit the screen (use screen -r if you want to connect to it again)(this disconects us from that virtual screen where idena node is running but leaves it running in background, so we can exit Putty without stopping idena node)
f. nano /home/datadir/api.key
copy that code that you get and save it somewhere on PC
(nano is like notepad for linux, we use it to open api.key file, you need api.key which is password for accessing your node so you can connect from idena app on your PC)
9. Now, close Putty and open it up so we can save connection and tunnel settings. Setup tunnel for connection as showed in this picture
In source enter:
9999In destination enter:
localhost:9009After you click Add, tunnel is saved. Next step is to save your IP address and connection. Go back to first option on top "Session" in Putty, in Host Name enter your vps IP address as before, in Saved Sessions enter name "vps connection" and press "Save button".
Now we have saved connection details with tunnel, so next time you open Putty you can doubleclick on saved "vps connection" and your login to vps will appear.
10. Connect to server using putty as before, using root/password... but now we have node running and tunneled connection
11. Configure Idena client to use node on your VPS. Open idena on PC, go to settings>node turn off "Run built-in node", turn on "Connect to remote node", set:
Node address:
http://localhost:9999Node api key:
that key that you saved previously using nanoSave both settings
12. Now check if you have some idena address by going to My Idena, you'll have some new address(robot) that is not yours. This is normal because you've run new node that generated new address.
13. Now you can transfer your private key/nodekey/identity to the VPS. We must find it on your PC, go to
%userprofile%\AppData\Roaming\Idena\node\datadir\keystore(best if you copy paste this in some folders address) there you will find nodekey file. Open it with notepad and copy it.
ALSO, IMPORTANT, BACKUP THIS, THIS IS YOUR PRIVATE KEY, DON'T SHARE IT WITH ANYONE.
14. Now we must put it on VPS. In Putty, run nano to edit nodekey file on vps so you can paste it there
nano /home/datadir/keystore/nodekey
this will open current private key on VPS, you must delete it and paste your from PC. Make sure you don't have any unnessessary blank spaces or new lines. After paste, just exit nano Ctrl+X when it asks you to save, save it by pressing Y and confirm file name by pressing Enter. Now you have transfered your identity to VPS.
15. We must restart node on VPS so it runs with new key/identity
screen -r - return to running node
Ctrl+C - shut the node downcd /home - change directory from current /root to the /home where the node is
screen -d -m ./idena-go - run it again in a detached screen
Now when you go to client, you should see your identity/address/robot.
Now, you need to connect Putty every time you want to open Idena client on PC (when making flips, doing validation, sending coins etc...)
But node runs and mines on VPS with or without Idena client.
So... this setup might take some time, make sure to check if mining is on, after all that you've done.
Adding a Swap file (virtual memory)
If you are running vps with a 1GB memory, it would be wise to enable swap (virtual memory) in case your vps runs low on memory
Enter this command to make additional 1GB swap memmory:
sudo fallocate -l 1G /swapfile2 && sudo chmod 600 /swapfile2 && sudo mkswap /swapfile2 && sudo swapon /swapfile2 && echo '/swapfile2 none swap sw 0 0' | sudo tee -a /etc/fstab
Pre-validation checkup
As node works, over time it starts to take more and more memory of the system. On the start it uses about 200mb of RAM memory. If it runs for a week or so, it can reach up to 700mb. It is very recomended to restart your node one day before validation so it clears up RAM memory so your validation runs without problems.
You can restart node with commands:
killall screen
cd /home
screen -d -m ./idena-go
Idena manager
Also take a look at comunity made script Idena Manager, this is all in one automated script to setup, run and update your node:
https://gitlab.com/crackowich/idena-manager
If your node is failing for some reason, try to run it as a remote node, localy. Here is step by step instructions on how to do it on a Windows PC:
1. On location
2. In client Settings>Node, turn off Run built-in node
3. Run previously created run.bat file
4. From location
5. In client, turn on Connect to remote host, paste api key and Save
1. On location
%userprofile%\AppData\Roaming\Idena\node create run.bat file with content:@echo off
:start
idena-go.exe
timeout /t 5
goto start2. In client Settings>Node, turn off Run built-in node
3. Run previously created run.bat file
4. From location
%userprofile%\AppData\Roaming\Idena\node\datadir open api.key with notepad and copy that key5. In client, turn on Connect to remote host, paste api key and Save
This tutorial is made to be acompanied by this video. Make sure to watch it alongside going through this instructions
This setup has many advantages:
- Node runs/mines in background
- Idena client/app does not have to be turned on, all the time
- Mining is more stable than running Built-in node and has autorestart feature
- If your PC restarts or updates, node starts automatically by itself
- You don't have to be logged in in order for node to run
In order to be able to make this setup, your Windows user account must be protected with password.
Setting password is also generally recommended to secure your PC.
Follow few easy steps which are also showed in the video:
1. Go to the node file location:
(copy Ctrl+C this path so you can paste it Ctrl+V as I did in video)
2. Copy the path to the datadir folder, we will need it for next steps
3. Open Task Scheduler - create new basic task and set it up like in a video
- chose idena-go (node) as program to be started
- add argument to configure node
4. Configure task to restart itself if it fails
5. Stop Built-In node, in Idena app go to Settings>Node and turn off "Run built-in node" and turn on "Connect to remote node"
6. Start node using Task that we just created, right click on it and select "Run".
7. Go to
8. Copy this key and paste it in Idena App, after that click on both Save buttons.
9. As we are here, we just might as well do the most important thing there is to do, make a backup of a nodekey file as shown in video. In the video, I just made a copy of nodekey to the desktop. Please make sure you store it some place safe like some cloud storage of your preference.
10. Now we can close Idena App (client) and the node (idena-go) will continue running in background.
11. If you open up Idena App again, it will connect to the background running node automatically. Just wait a few seconds.
12. Learn how to run or stop node from Task Scheduler as shown in the video. You will need this in order to make easy node update when needed.
Only disadvantage of running node as a background task is a bit complicated node update procedure:
- Stop node task
- Switch to built in node from App settings
- Update node by clicking update button in App
- Switch to remote node in App settings
- Run task again
This setup has many advantages:
- Node runs/mines in background
- Idena client/app does not have to be turned on, all the time
- Mining is more stable than running Built-in node and has autorestart feature
- If your PC restarts or updates, node starts automatically by itself
- You don't have to be logged in in order for node to run
In order to be able to make this setup, your Windows user account must be protected with password.
Setting password is also generally recommended to secure your PC.
Follow few easy steps which are also showed in the video:
1. Go to the node file location:
%userprofile%\AppData\Roaming\Idena\node(copy Ctrl+C this path so you can paste it Ctrl+V as I did in video)
2. Copy the path to the datadir folder, we will need it for next steps
%userprofile%\AppData\Roaming\Idena\node\datadir3. Open Task Scheduler - create new basic task and set it up like in a video
- chose idena-go (node) as program to be started
- add argument to configure node
--datadir=C:\Users\{your user name}\AppData\Roaming\Idena\node\datadir4. Configure task to restart itself if it fails
5. Stop Built-In node, in Idena app go to Settings>Node and turn off "Run built-in node" and turn on "Connect to remote node"
6. Start node using Task that we just created, right click on it and select "Run".
7. Go to
%userprofile%\AppData\Roaming\Idena\node\datadir and open api.key with notepad.8. Copy this key and paste it in Idena App, after that click on both Save buttons.
9. As we are here, we just might as well do the most important thing there is to do, make a backup of a nodekey file as shown in video. In the video, I just made a copy of nodekey to the desktop. Please make sure you store it some place safe like some cloud storage of your preference.
10. Now we can close Idena App (client) and the node (idena-go) will continue running in background.
11. If you open up Idena App again, it will connect to the background running node automatically. Just wait a few seconds.
12. Learn how to run or stop node from Task Scheduler as shown in the video. You will need this in order to make easy node update when needed.
Only disadvantage of running node as a background task is a bit complicated node update procedure:
- Stop node task
- Switch to built in node from App settings
- Update node by clicking update button in App
- Switch to remote node in App settings
- Run task again
If your node is failing for some reason, try to run it as a remote node, localy. Here is step by step instructions on how to do it on a Linux PC:
1. Go to home directory using File Manager, press Ctrl+H key combination to show hidden items.
2. Proceed to location
3. In client Settings>Node, turn off Run built-in node
4. Run previously created run.sh file
5. From location
6. In client, turn on Connect to remote host, paste api key and Save.
1. Go to home directory using File Manager, press Ctrl+H key combination to show hidden items.
2. Proceed to location
.config/Idena/node, create run.sh file with content:while true
do
./idena-go
sleep 10
done3. In client Settings>Node, turn off Run built-in node
4. Run previously created run.sh file
5. From location
.config/Idena/node/datadir open api.key with any text editor and copy that key6. In client, turn on Connect to remote host, paste api key and Save.
Take a look at a video, made by Fomonout and Set Animals to show you few tips on what is good and what is bad when making flips
https://www.youtube.com/watch?v=8nsDJJzyth4
https://www.youtube.com/watch?v=8nsDJJzyth4
1. Turn off bat that's been running node
2. In Idena app, switch to Run built-in node
3. Update node in Idena app
4. Switch back to Remote node
5. Run bat file again which runs node
2. In Idena app, switch to Run built-in node
3. Update node in Idena app
4. Switch back to Remote node
5. Run bat file again which runs node
No, it will bug out network and you will gain less DNA than running one node. In future, this will get you penalties.
Fell free to register on this portal and add your idena node address to the mining monitoring so you get notifications when your node goes offline for whatever reason. That way you will avoid getting penalty and together we can troubleshoot it and try to prevent it from happening again.
Why am I getting black screen during validation in short session? black screen short session validation
- Take in consideration that short session is 1:45 minutes long, not 2 minutes. So If you have 1:45 minutes at start, that is allright.
- If you are running multiple Idena apps in same household, your router maybe can't handle great number of connections and your session takes longer to load.
- If you are running remote node, maybe your internet connection/router is failing.
- If you are running remote node, there is possibility that your OS where the node is, and OS where the client is, are not synced to the same time. If you experience black screen for few seconds, check if both computers are in sync. You can check time sync by visiting this link.
- Also if you get black screen, or no flips loading or partialy loading, try to wait few seconds and try to click left and right and change flips to encourage idena app to try and load flips again.
- If you are running multiple Idena apps in same household, your router maybe can't handle great number of connections and your session takes longer to load.
- If you are running remote node, maybe your internet connection/router is failing.
- If you are running remote node, there is possibility that your OS where the node is, and OS where the client is, are not synced to the same time. If you experience black screen for few seconds, check if both computers are in sync. You can check time sync by visiting this link.
- Also if you get black screen, or no flips loading or partialy loading, try to wait few seconds and try to click left and right and change flips to encourage idena app to try and load flips again.
How to delete Flip that is missing on client? delete flip
1. Find your flip hash that you want to delete on Idena explorer
2. Visit http://rpc.idena.io
3. Enter your parameters to connect to the node in the top of window.
4. Go to Flip API, then to Delete flip section
5. Enter hash of your flip from explorer and click on Submit request
Wait a minute and your flip should be deleted.
2. Visit http://rpc.idena.io
3. Enter your parameters to connect to the node in the top of window.
4. Go to Flip API, then to Delete flip section
5. Enter hash of your flip from explorer and click on Submit request
Wait a minute and your flip should be deleted.
That was one of security update to the network:
Discrimination of identities with the Newbie status
- 80% of all earned coins will be frozen in the stake wallet until a Newbie becomes Verified
- 20% of earned coins will be mined to the main wallet
- 60% of staked coins will be sent back to the main wallet once a Newbie becomes Verified
- A Newbie will not be able to terminate their identities to withdraw the stake.
Motivation: Decreasing rewards for bots which have no intention to get the Verified status. Honest participants will not be penalized since they get their frozen coins back once they reach the Verified status.
Read full article with this update
Discrimination of identities with the Newbie status
- 80% of all earned coins will be frozen in the stake wallet until a Newbie becomes Verified
- 20% of earned coins will be mined to the main wallet
- 60% of staked coins will be sent back to the main wallet once a Newbie becomes Verified
- A Newbie will not be able to terminate their identities to withdraw the stake.
Motivation: Decreasing rewards for bots which have no intention to get the Verified status. Honest participants will not be penalized since they get their frozen coins back once they reach the Verified status.
Read full article with this update
What does missing flip means flip missing
That means that you have made a flip and it's safely stored on Idena network. You don't have to worry about it.
This can happen if you've made flips in Desktop App, and now you are looking in Web App or the other way around.
Or you have reinstalled your Idena, so it does not have cache images of that flip.
You are ready for next validation. As your current task probably tells you.
This can happen if you've made flips in Desktop App, and now you are looking in Web App or the other way around.
Or you have reinstalled your Idena, so it does not have cache images of that flip.
You are ready for next validation. As your current task probably tells you.
It is possible that your node is running fine and it is syncronysed but you can't turn mining on or off. It's because you got stuck transaction. We must send few transactions manualy until nonce (transaction order number) gets cleared. You can solve it this way.
1. Visit http://rpc.idena.io
2. Connect to your node

For address, you enter "http://localhost:9119" this is same for everyone. But you will have to find your own api key. Find api key here, open file api key and copy it
%appdata%/Idena/node/datadir/api.key
3. Let’s check which transaction is stuck and what is it’s nonce number. Go to "Get address pending txs" section. Enter your Idena address and click “Send request”.

If it say "Something went wrong" you did not connect to the node correctly, check your api key.
If it's OK, you will get list of transactions that are stuck. You need to go to the bottom transaction and see what nonce value it has. Let’s say it has “nonce”: “9”
4. Head out to "Send DNA" section and fill fields like this, enter your Idena address in “From” and “To” fields. 0.05 in “Amount” and 1 in “Nonce”.
This will send 0.05 iDNA to your own address. We need to repeat this transaction up untill nonce that we saw earler “9”. So in this case, repeat transactions but change nonce to 2, 3, 4, 5, 6, 7, 8. After you have sent transactions, wait 30 seconds to see if your past transactions were cleared in IdenaApp on Wallet page.
If your "Turn on mining" transaction is still stuck, try to restart Idena App.
1. Visit http://rpc.idena.io
2. Connect to your node
For address, you enter "http://localhost:9119" this is same for everyone. But you will have to find your own api key. Find api key here, open file api key and copy it
%appdata%/Idena/node/datadir/api.key
3. Let’s check which transaction is stuck and what is it’s nonce number. Go to "Get address pending txs" section. Enter your Idena address and click “Send request”.
If it say "Something went wrong" you did not connect to the node correctly, check your api key.
If it's OK, you will get list of transactions that are stuck. You need to go to the bottom transaction and see what nonce value it has. Let’s say it has “nonce”: “9”
4. Head out to "Send DNA" section and fill fields like this, enter your Idena address in “From” and “To” fields. 0.05 in “Amount” and 1 in “Nonce”.
This will send 0.05 iDNA to your own address. We need to repeat this transaction up untill nonce that we saw earler “9”. So in this case, repeat transactions but change nonce to 2, 3, 4, 5, 6, 7, 8. After you have sent transactions, wait 30 seconds to see if your past transactions were cleared in IdenaApp on Wallet page.
If your "Turn on mining" transaction is still stuck, try to restart Idena App.
Yes, but there is a limit per identity status:
- Newbie must make 3 flips and that is maximum that he can make
- Verified must make 3 flips and have 1 more optional, so 4 maximum
- Human must make 3 flips and have 2 more optional, so 5 maximum
But be aware that if any of your flip gets reported, you lose reward for all flips, validation and invitations.
That said, do not force yourself to make maximum flips if you don't have good words combination.
- Newbie must make 3 flips and that is maximum that he can make
- Verified must make 3 flips and have 1 more optional, so 4 maximum
- Human must make 3 flips and have 2 more optional, so 5 maximum
But be aware that if any of your flip gets reported, you lose reward for all flips, validation and invitations.
That said, do not force yourself to make maximum flips if you don't have good words combination.
You are rewarded for running your own node and maintaining Idena network.
You are rewarded because you provide service of node hosting (internet/power/computation).
Key and power of decentralised network are, if some nodes go offline, other are still working and network continues working.
Not anyone can run node, only those who prove themselves to be human by validation process.
When you validate, your node can be a part of network.
You can run 2 nodes with same identity in different locations (disaster recovery strategy).
But running 2 nodes will get you less mining rewards. Also running multiple nodes is more expensive for you.
You decide how you're gonna provide your node hosting service for Idena. At home or go for VPS.
It's same with ISP, when they have some problem, you call them and they fix your internet.
Well in our case, Idena network can not call us, but gets us penalty. As we did not provide node hosting service well enough.
And penalty incentivises users to try and host node in best way that is available to them so the network can have more up time and be more reliable.
How is mining penalty calculated?
Mining penalty is always about 8 hours of mining. So if 25,920 iDNA are available daily, divide that by number number of people who are mining right now to get amount for 24h. Divide that by 3 to get 8 hours and you will get penalty amount in iDNA. Those are not taken from your earned coins but you are mining/burning iDNA for next 8 hours without getting reward.
You are rewarded because you provide service of node hosting (internet/power/computation).
Key and power of decentralised network are, if some nodes go offline, other are still working and network continues working.
Not anyone can run node, only those who prove themselves to be human by validation process.
When you validate, your node can be a part of network.
You can run 2 nodes with same identity in different locations (disaster recovery strategy).
But running 2 nodes will get you less mining rewards. Also running multiple nodes is more expensive for you.
You decide how you're gonna provide your node hosting service for Idena. At home or go for VPS.
It's same with ISP, when they have some problem, you call them and they fix your internet.
Well in our case, Idena network can not call us, but gets us penalty. As we did not provide node hosting service well enough.
And penalty incentivises users to try and host node in best way that is available to them so the network can have more up time and be more reliable.
How is mining penalty calculated?
Mining penalty is always about 8 hours of mining. So if 25,920 iDNA are available daily, divide that by number number of people who are mining right now to get amount for 24h. Divide that by 3 to get 8 hours and you will get penalty amount in iDNA. Those are not taken from your earned coins but you are mining/burning iDNA for next 8 hours without getting reward.
Track your wallet balance in google sheet track balance
https://github.com/Netz00/IdenaWalletBalanceTracker
We don't have simple solution for this currently, but it's doable. You have two options:
1. Make your node open and publically available, but only you will be able to access it, because only you know api key
- setup strong api key
- run node so it listens on vps ip address, run node with parameter --rpchost=123.22.33.44 (ip of your vps)
- apply ssl certificate for your ip/better yet if you have some domain (maybe you can do it with certbot, free ssl certs)
2. Use some app that will make ssh tunnel to your vps, and you can use localhost:9009 to connect to your vps
1. Make your node open and publically available, but only you will be able to access it, because only you know api key
- setup strong api key
- run node so it listens on vps ip address, run node with parameter --rpchost=123.22.33.44 (ip of your vps)
- apply ssl certificate for your ip/better yet if you have some domain (maybe you can do it with certbot, free ssl certs)
2. Use some app that will make ssh tunnel to your vps, and you can use localhost:9009 to connect to your vps
Mining rewards mining rewards
Block reward is 6 iDNA, block time is 20 seconds
There is cap of 25,920 iDNA minted daily, so divide that by the number of validators and you get your average 24h mining reward.
Commitie of 100 is selected to vote on a block, example
https://scan.idena.io/block/4016024
The 6 iDNA from every block get split like this: 1 iDNA for the issuer, and 5 iDNA for the validators. For 100 validators that means every verified block would be 0.05 iDNA for each validator.
There is cap of 25,920 iDNA minted daily, so divide that by the number of validators and you get your average 24h mining reward.
Commitie of 100 is selected to vote on a block, example
https://scan.idena.io/block/4016024
The 6 iDNA from every block get split like this: 1 iDNA for the issuer, and 5 iDNA for the validators. For 100 validators that means every verified block would be 0.05 iDNA for each validator.
When you create your flips, images are shared across IPFS share space in Idena blockchain. More precisely, on 33% of nodes in the network.
Your keywords are not shared, they are known only to your identity. During validation, they are decrypted and sent to needed identities which are solving those flips.
So if the person who created flips that you are solving, is using Web App, and did not login 5 min before validation, or has crappy connection, words are not available. Same for Desktop App, if a persons node is not online, or has connection problems, it will not decrypt words and they will not be visible.
If a person has stupid problems with his node, and node recovers during validation long session, you can still receive those words. So you can wait some time, and if they are not loaded, you can skip flip
Your keywords are not shared, they are known only to your identity. During validation, they are decrypted and sent to needed identities which are solving those flips.
So if the person who created flips that you are solving, is using Web App, and did not login 5 min before validation, or has crappy connection, words are not available. Same for Desktop App, if a persons node is not online, or has connection problems, it will not decrypt words and they will not be visible.
If a person has stupid problems with his node, and node recovers during validation long session, you can still receive those words. So you can wait some time, and if they are not loaded, you can skip flip
An answer from devs regarding POS, Nothing at stake and Long range attacks
Here is some explanation about that bug that happened and how I understood what was the problem...
Q: Why was I killed, I had great PC / VPS, 16GB of ram and 6 core CPU?
A: The whole network stopped, no one killed anyone, the whole network "killed itself" in a way. I understand that, that kind of powerful node is one of those who participated in making those big blocks, but your results were not in the first but in the second block that was made late.
If you participate in the committee for making blocks, approximately, I'm not sure how big that committee is, that is, how many nodes it consists of. All participating nodes in committee must process all transactions within 20sec of the block's duration. What happened was, too many transactions from too many participants.

3420 nodes performed validation. In the previous successful validation, 2300 nodes passed, which means that the network worked with 47.8% more nodes than last time, which means that the load is so much higher, that is. number of transactions. The block reached a maximum size, 1MB, other transactions were waiting in the mempool to be put in next block. Then the network tried to process that block in order for those transactions to become valid (ie. our answers on validation).
Then, a committee of random nodes is made.
And every node in that committee must process that, so far the largest block we have ever had.
The nodes in the committee were changing all the time trying to process that huge block. But were not able and network made empty blocks.
Until the network came up with stronger nodes (like VPS's and home PC's that had multicores and higher RAM), and they managed to process that block, f**in near the end of validation. Those transactions(validation answers) processed in that block have passed validation, because those transactions are on the processed block and are written to the blockchain.
The next committee is again a failure and an empty block.
After that, when it was already late, the second block was processed (also almost full 1MB block), which contained the other half of our answers/transactions.
Now... The developers will make sure that validation cannot be completed while there are still unprocessed validation transactions in mempool. The worst that can now happen is to wait for the validation result for few blocks longer. Additionally, since it will reduce the maximum block size to 300KB from 1MB, that means it will be 3x easier for all nodes to process blocks.
Q: So what now? Will they kick us out who have 1cpu/1gb or?
A: No, these nodes will work now as well, because they will be 3x less demanding blocks.
Q: And what will happen for the next validation when we have 3000 nodes again?
A: Since there will be less demanding blocks, all nodes should be able to process them and that's only... 10 blocks.
If we calculate that in the last validation we needed 2 blocks of 1MB for all answers. This means we need 2MB of data for all responses to be written. Let's think that in the next validation we will have not 2MB as we had now, let's consider 3MB. Since the block will be 300KB, this means that we will need to process 10 blocks in order for all transactions (all validation responses) to be successfully written on blockchain.
Since the block lasts 20 seconds and we need 10 blocks, that is, we need 3.5 minutes.
And we know that a long session lasts 30 minutes, which means we have 8x more time than we need.
With this principle, we can roughly calculate the following theoretical maximum of the network before validation sharding must be implemented.
Q: And now the question, why didn't they remember that before? But when did it break?
A: It broke because we reached the maximum with testing. If no one had tested, no one would have ever found out about this what we found out. They themselves said they did not expect this.
I guess the problem was also VPSs that have 1Core/1GB. When the 1GB of memory is full, then it switches to SWAP which is actually a slow hard drive. Then for that, the processor needs much more time to allocate memory to RAM and SWAP. And that leads to the impossibility to do everything properly, that is, does not have enough CPU power to process that large block of 1MB transactions.
I also figured out what our maximum transactions were. There yeah were 3966 transactions in that first big block, let's say 4000.
4000tx / 20sec block time, so 200 transactions per second, what is the speed tx/s in ETH?
On ETH the max is 15tx/s.
And do you know what ETH is working on? What are those nodes? They are certainly not a $5 VPS. They run on powerful Amazon instances.
And ETH has 7800 nodes.
Not even Idena can work on Tetris hardware.
After reducing the block size 3x, we will again be at 4x faster transaction speed than ETH.
At about 66 tx/s, even with tetris computers.
My recommendation is to temporarily upgrade each VPS for validation to 2GB.
Digital Ocean is great for that, they support temporary component changes. One can even make a script that Digital Ocean itself does upscale 2GB for validation and downscale 1GB afterwards, automatically via API. I remember that Anthrophobia and Crackowich told me that they were doing it. Validation means testing the theoretical maximum of the network each time.
Node operation during mining, while there are barely a couple of transactions in each block, is nothing compared with node operation during validation.
And this is what we deal in the network, this member is complaining that syncing is slow, and has 5/0.2 internet speed...

Q: Why was I killed, I had great PC / VPS, 16GB of ram and 6 core CPU?
A: The whole network stopped, no one killed anyone, the whole network "killed itself" in a way. I understand that, that kind of powerful node is one of those who participated in making those big blocks, but your results were not in the first but in the second block that was made late.
If you participate in the committee for making blocks, approximately, I'm not sure how big that committee is, that is, how many nodes it consists of. All participating nodes in committee must process all transactions within 20sec of the block's duration. What happened was, too many transactions from too many participants.
3420 nodes performed validation. In the previous successful validation, 2300 nodes passed, which means that the network worked with 47.8% more nodes than last time, which means that the load is so much higher, that is. number of transactions. The block reached a maximum size, 1MB, other transactions were waiting in the mempool to be put in next block. Then the network tried to process that block in order for those transactions to become valid (ie. our answers on validation).
Then, a committee of random nodes is made.
And every node in that committee must process that, so far the largest block we have ever had.
The nodes in the committee were changing all the time trying to process that huge block. But were not able and network made empty blocks.
Until the network came up with stronger nodes (like VPS's and home PC's that had multicores and higher RAM), and they managed to process that block, f**in near the end of validation. Those transactions(validation answers) processed in that block have passed validation, because those transactions are on the processed block and are written to the blockchain.
The next committee is again a failure and an empty block.
After that, when it was already late, the second block was processed (also almost full 1MB block), which contained the other half of our answers/transactions.
Now... The developers will make sure that validation cannot be completed while there are still unprocessed validation transactions in mempool. The worst that can now happen is to wait for the validation result for few blocks longer. Additionally, since it will reduce the maximum block size to 300KB from 1MB, that means it will be 3x easier for all nodes to process blocks.
Q: So what now? Will they kick us out who have 1cpu/1gb or?
A: No, these nodes will work now as well, because they will be 3x less demanding blocks.
Q: And what will happen for the next validation when we have 3000 nodes again?
A: Since there will be less demanding blocks, all nodes should be able to process them and that's only... 10 blocks.
If we calculate that in the last validation we needed 2 blocks of 1MB for all answers. This means we need 2MB of data for all responses to be written. Let's think that in the next validation we will have not 2MB as we had now, let's consider 3MB. Since the block will be 300KB, this means that we will need to process 10 blocks in order for all transactions (all validation responses) to be successfully written on blockchain.
Since the block lasts 20 seconds and we need 10 blocks, that is, we need 3.5 minutes.
And we know that a long session lasts 30 minutes, which means we have 8x more time than we need.
With this principle, we can roughly calculate the following theoretical maximum of the network before validation sharding must be implemented.
Q: And now the question, why didn't they remember that before? But when did it break?
A: It broke because we reached the maximum with testing. If no one had tested, no one would have ever found out about this what we found out. They themselves said they did not expect this.
I guess the problem was also VPSs that have 1Core/1GB. When the 1GB of memory is full, then it switches to SWAP which is actually a slow hard drive. Then for that, the processor needs much more time to allocate memory to RAM and SWAP. And that leads to the impossibility to do everything properly, that is, does not have enough CPU power to process that large block of 1MB transactions.
I also figured out what our maximum transactions were. There yeah were 3966 transactions in that first big block, let's say 4000.
4000tx / 20sec block time, so 200 transactions per second, what is the speed tx/s in ETH?
On ETH the max is 15tx/s.
And do you know what ETH is working on? What are those nodes? They are certainly not a $5 VPS. They run on powerful Amazon instances.
And ETH has 7800 nodes.
Not even Idena can work on Tetris hardware.
After reducing the block size 3x, we will again be at 4x faster transaction speed than ETH.
At about 66 tx/s, even with tetris computers.
My recommendation is to temporarily upgrade each VPS for validation to 2GB.
Digital Ocean is great for that, they support temporary component changes. One can even make a script that Digital Ocean itself does upscale 2GB for validation and downscale 1GB afterwards, automatically via API. I remember that Anthrophobia and Crackowich told me that they were doing it. Validation means testing the theoretical maximum of the network each time.
Node operation during mining, while there are barely a couple of transactions in each block, is nothing compared with node operation during validation.
And this is what we deal in the network, this member is complaining that syncing is slow, and has 5/0.2 internet speed...
Make a run_node.bat file with next content
Instructions:
1. Quit your IdenaApp
2. Run the bat file.
@echo off
FOR /F "tokens=4 delims= " %%i in ('route print ^| find " 0.0.0.0"') do set localIp=%%i
echo ------------------------------------------------------------
echo ------------- Settings for my Idena mobile app -------------
echo ------------------------------------------------------------
echo Node address: http://%localIp%:9009
echo Node api key: 123
echo ------------------------------------------------------------
echo ------------------------------------------------------------
echo After you have finished entering information in mobile app settings,
pause
%userprofile%\AppData\Roaming\Idena\node\idena-go.exe --rpcaddr=%localIp% --rpcport=9009 --apikey=123Instructions:
1. Quit your IdenaApp
2. Run the bat file.
Delete ipfs faster on windows delete ipfs
Open command prompt
Go to ipfs folder
DEL /F/Q/S *.* > NUL
Or you can just rename it if you're in a hurry and delete it later when you have more time.
Go to ipfs folder
DEL /F/Q/S *.* > NUL
Or you can just rename it if you're in a hurry and delete it later when you have more time.
idena-manager disable
rm log*
cd datadir-node1
rm -r ipfs
rm -r logs
idena-manager enable
rm log*
cd datadir-node1
rm -r ipfs
rm -r logs
idena-manager enable
curl 'http://localhost:9009/' -H 'Content-Type:application/json' --data '
{"method": "dna_sendTransaction",
"params": [{
"from": "0x3768b3a30532521fda0bf959fbbc92b4c35e93fc",
"to": "0x1264fa88e461c46a97687da81c9e57d803e83663",
"amount": "3"
}],
"id": 4,
"key": "apikey"
}'
{"method": "dna_sendTransaction",
"params": [{
"from": "0x3768b3a30532521fda0bf959fbbc92b4c35e93fc",
"to": "0x1264fa88e461c46a97687da81c9e57d803e83663",
"amount": "3"
}],
"id": 4,
"key": "apikey"
}'
The block proposer sets the time of the block (which is usually calculated by adding time between blocks to the previous block time, but it can be moved forward to proposer's local time if blocks are lagging) and the committee validates that the chosen timestamp is correct. Those block timestamps are used to determine ceremony timing.
So there's no explicit time synchronization happening, the network just requires you to be in sync with the majority or you'll get errors when proposing or validating blocks.
So there's no explicit time synchronization happening, the network just requires you to be in sync with the majority or you'll get errors when proposing or validating blocks.
I have sent my iDNA coins to Metamask or Trust wallet address without using Bridge metamask trust wallet
You are in luck because Idena addresses are compatible with Ethereum and Binance Smart Chain. You can get them back.
1. Export your private key from Trust wallet/Metamask
2. Encrypt that key here: Encrypt tool
For password, make up some new password.
If you use Trust Wallet, you need to delete "0x" from key beginning before encrypting it.
3. Use those key and password to sign in to Idena Web App wallet app.idena.io
4. When it asks you for Invitation code, click "Skip"
Now you will see your coins and you can send them from Wallet.
1. Export your private key from Trust wallet/Metamask
2. Encrypt that key here: Encrypt tool
For password, make up some new password.
If you use Trust Wallet, you need to delete "0x" from key beginning before encrypting it.
3. Use those key and password to sign in to Idena Web App wallet app.idena.io
4. When it asks you for Invitation code, click "Skip"
Now you will see your coins and you can send them from Wallet.
I have sent my WiDNA tokens from Metamask or Trust Wallet to Idena address without using Bridge metamask bsc
Idena has its own network so you need to use Bridge to transfer WiDNA from BSC to Idena network and get iDNA. But you are in luck, addresses are compatible so your coins are not lost. You need to retreive them.
What you need to do is:
1. Get your Idena private key
a) If you have sent coins to Idena Desktop App, find idena private key like shown in this video.
b) If you have sent coins to Idena Web App you need to decrypt your idena private key
- go here
Decrypt tool
- use this form
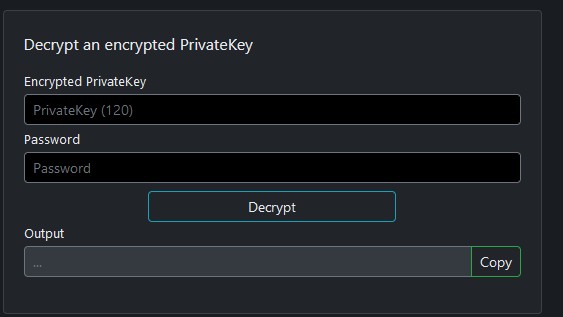
- enter your idena private key and password you used to create new Idena account and chose Decrypt, you will get private key in Output field, copy it.
2. Now, using that key that you just found and copied, you need to import it in Metamask or Trust wallet
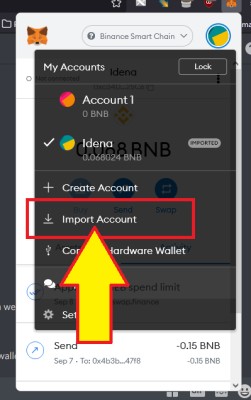
3. Swap your WiDNA tokens to Idena wallet using Bridge
- Now when you have access to your tokens on Metamask / Trust wallet
- Now you can use Bridge to swap your WiDNA from BSC to iDNA on Idena network
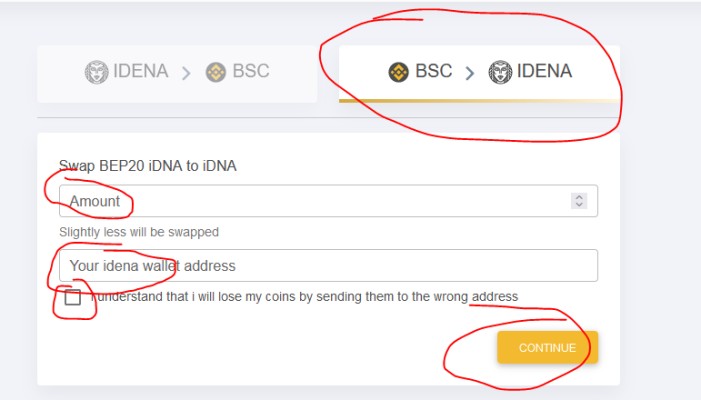
What you need to do is:
1. Get your Idena private key
a) If you have sent coins to Idena Desktop App, find idena private key like shown in this video.
b) If you have sent coins to Idena Web App you need to decrypt your idena private key
- go here
Decrypt tool
- use this form
- enter your idena private key and password you used to create new Idena account and chose Decrypt, you will get private key in Output field, copy it.
2. Now, using that key that you just found and copied, you need to import it in Metamask or Trust wallet
3. Swap your WiDNA tokens to Idena wallet using Bridge
- Now when you have access to your tokens on Metamask / Trust wallet
- Now you can use Bridge to swap your WiDNA from BSC to iDNA on Idena network
You did advanced "invite person using his address" thing, next thing he must do is just click on "Activate" button, no matter if his invitation field is empty.
Because while in PoS globally (single shard) it is really hard to have enough stake for bad actors to take over the network, often times because of whales and the difficulty of coordination between them all, in smaller shards it is much easier because the aforementioned whales wouldn't have to compete against each other and can control those shards easier. So, while globally a turbowhale would have let's say 10% of the total stake, in a shard they'd have much more like 25% if not more. Their power grows in shards. in PoP, relatively speaking, it is as equally hard to control the global system as it is in a smaller shard. In any of those cases, a person would have 1/n power globally or in a shard where n is the number of actors either in the shard or globally
of course, within shards there will be less people in PoP, so each person will in fact have more power, but to take over the system they'd still have to coordinate with 33%-51% (i think its 33% in PoS-type of systems?) of unique individuals in the shard. Whereas for PoS, whales have to coordinate with fewer and fewer individuals the less money there is in the shard
the 10% and 25% i wrote above in the whale PoS scenario are made up and just for the sake of an example.
-Tirion
of course, within shards there will be less people in PoP, so each person will in fact have more power, but to take over the system they'd still have to coordinate with 33%-51% (i think its 33% in PoS-type of systems?) of unique individuals in the shard. Whereas for PoS, whales have to coordinate with fewer and fewer individuals the less money there is in the shard
the 10% and 25% i wrote above in the whale PoS scenario are made up and just for the sake of an example.
-Tirion
Idena use cases use cases
Current:
- Payment network (as any other blockchain)
- Idena Oracles - tool for decentralised governance
- Anti Sybil identity solution used by Gitcoin
- Source of UBI for some of its users
- Hosting your own website
- Idena sign in option, available for implementation
Future:
- With future full smart contract developed, it will enable any other usecase that is available on any other blockchain network
- Attention economy - Onchain advertising
- Freedom of speech - you can see things like decentralised messanger which are on the roadmap
https://docs.idena.io/docs/wp/roadmap
- Payment network (as any other blockchain)
- Idena Oracles - tool for decentralised governance
- Anti Sybil identity solution used by Gitcoin
- Source of UBI for some of its users
- Hosting your own website
- Idena sign in option, available for implementation
Future:
- With future full smart contract developed, it will enable any other usecase that is available on any other blockchain network
- Attention economy - Onchain advertising
- Freedom of speech - you can see things like decentralised messanger which are on the roadmap
https://docs.idena.io/docs/wp/roadmap
wget https://raw.githubusercontent.com/rioda-org/idena/main/shared-node-proxy-update.sh && bash shared-node-proxy-update.sh
For this to work, your api key needs to be 123.
Copy this code in your terminal and it will take care of the rest
wget https://raw.githubusercontent.com/rioda-org/idena/main/replenish-stake-install.sh && bash replenish-stake-install.sh
How does it work?
It installs jq, thing that makes it easier to work with json content.
It downloads script that will automatically stake your balance.
It sets up task to run auto stake once a day at midnight UTC.
Script will read your balance, subtract 2 idna from it and and stake the rest.
Copy this code in your terminal and it will take care of the rest
wget https://raw.githubusercontent.com/rioda-org/idena/main/replenish-stake-install.sh && bash replenish-stake-install.sh
How does it work?
It installs jq, thing that makes it easier to work with json content.
It downloads script that will automatically stake your balance.
It sets up task to run auto stake once a day at midnight UTC.
Script will read your balance, subtract 2 idna from it and and stake the rest.